4. 軽量版カスタムレシピを用いた実習(所要時間:約1時間)
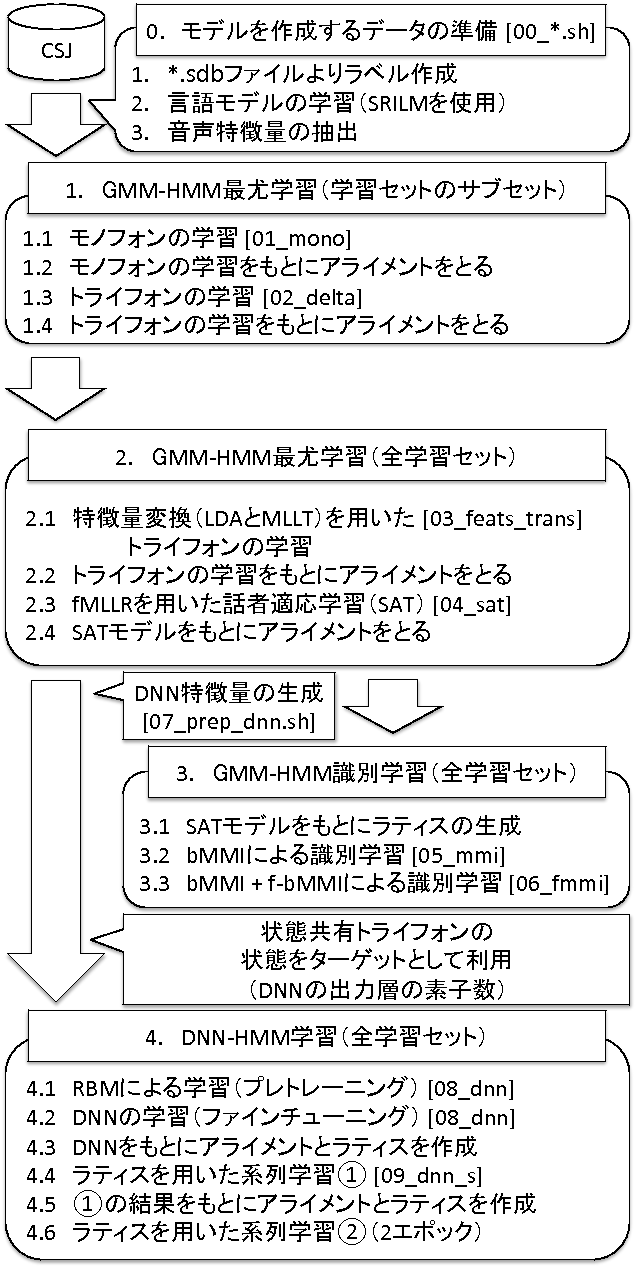
図1 CSJ kaldi レシピの構成
表1 実習で使用するCSJデータ(要別途入手)
| 音声 | 書き起こし |
| A01F0055.wav |
CSJ{DVD1 or MORPH}/SDB/coreに含まれる全短単位長単位混合形式形態論テータ*.sdbファイル 201講演 (左記の音声データに対応する講演のsdbを包含すれば,言語モデルが学習できる数の講演があればよい) |
| A01F0067.wav | |
| A01M0097.wav | |
| A01F0122.wav | |
| A01F0132.wav |
[kalditest@suzukake ~]$ su [root@suzukake]$ yum upgrade
[root@suzukake]$ yum install atlas-sse3-devel
[root@suzukake]$ yum install nkf
[kalditest@suzukake ~]$ cd ~ [kalditest@suzukake ~]$ git clone https://github.com/kaldi-asr/kaldi.gitインストール手順の詳細は各ディレクトリにあるINSTALLファイルに書かれています.
[kalditest@suzukake ~]$ cd kaldi [kalditest@suzukake kaldi]$ cd tools [kalditest@suzukake tools]$ make [kalditest@suzukake src]$ cd ../src [kalditest@suzukake src]$ ./configure [kalditest@suzukake src]$ make depend [kalditest@suzukake src]$ make
[kalditest@suzukake tools]$ cd ~/kaldi/tools [kalditest@suzukake tools]$ ./install_srilm.sh
[kalditest@suzukake tools]$ chmod o+rx openfst-1.3.4
[kalditest@suzukake ~]$ cd ~/kaldi/egs/csj/s5/ [kalditest@suzukake s5]$ source path.sh [kalditest@suzukake s5]$ copy-feats [kalditest@suzukake s5]$ nnet-copy
[kalditest@suzukake ~]$ tar zxf s5_demo.tgz [kalditest@suzukake ~]$ mv s5_demo ~/kaldi/egs/csj
[kalditest@suzukake ~]$ cd ~/kaldi/egs/csj/s5_demo
[kalditest@suzukake s5_demo]$ cp -ip "CSJのサブセット/{*.wav,*.sdb}" CSJ
図1 CSJ kaldi レシピの構成