[統計的音声認識の基本原理]
音声認識は,マイクから取り込んだ音声信号が表す内容を単語系列に変換して出力する技術です.
現在もっとも高い性能が得られているのが,統計的手法に基づいた統計的音声認識です.
1. 音声とスペクトル
マイクから取り込んだ音声信号は,一次元の時系列データです.横軸を時間,縦軸を音の大きさとしてグラフを作成すると,以下のような図が得られます.
この音声波形信号から,各時刻でどれくらいの周波数成分がどれくらい含まれているのかを調べることをスペクトル分析といいます.
スペクトル分析の結果を横軸を時間,縦軸をパワーとしてグラフにすると,以下のような図(スペクトログラム)が得られます.
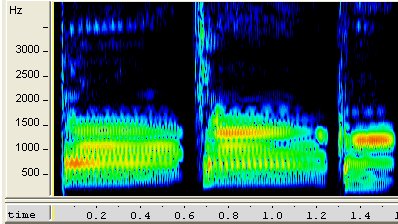
この周波数成分分布(スペクトル)の時間変化パターンが,その音声がどのような内容であるかの手がかりになります.
実際の音声認識ではこのスペクトルからさらに音声の特徴を効果的に抽出するための変換を何度か行います.
そして,最終的に数十次元のベクトルが数十ミリ秒に1個の割合で時間方向に並んだ特徴量系列を得ます.
例えば,特徴量の次元が40で10ミリ秒に1つの割合とすると,2秒間の音声信号の特徴は40次元のベクトル200個により表現されることになります.
2. 最大事後確率則
時系列音声特徴量をO,対応する単語列をWとすると,統計的音声認識の基本原理は以下のように簡潔に表現されます.
)
すなわち,入力された音声特徴量Oに対して,もっとも確率の高い単語列Wを探索して出力します.
この際,真の確率P(W|O)は不明なので,P(W|O)は予め作成した確率モデルを用いて計算します.この確率モデルのことを音声モデルと呼びます.
また,argmaxで表される探索操作を行うソフトウエアのことを音声認識デコーダと呼びます.
式で書くと単純ですが,ちょっと考えるとその探索空間は非常に大きいことが分かります.例えば3万語の語彙で10単語からなる文章の種類数は30000^10(=5.9E44)もあります.
これをまともに列挙してそれぞれに対してP(W|O)を評価し最大値を与えるWを探索するのは,実質不可能です.それをなんとかするために,音声認識では様々な工夫がされています.