[重みつき有限状態トランスデューサ]
重みつき有限状態トランスデューサ(WFST)は,入力シンボル,出力シンボルおよび遷移確率を持った有限状態マシンです.
WFSTは音声認識において近年利用が広まりつつあります.
音声認識で音響モデルとして用いられている隠れマルコフモデル(HMM)の状態遷移や,言語モデルとして用いられるNgramモデルなどはWFSTとして表現することが出来ます.
さらに,それらのWFSTを数学的に定義された合成演算を用いて一つのWFSTに変換することが出来ます.
1. WFSTを用いた音声認識
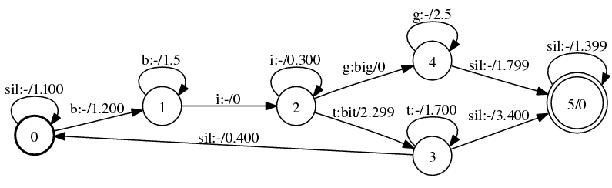
以下は音素状態の系列を入力として受け取り,単語を出力するWFSTの例です.
このネットワークでは入力として"sil","b","i","g","t" のどれかの音素状態シンボルを受け取り,単語"big"または"bit"を出力します.
また,この例で開始状態は0番ノードで,終了状態は5番ノードです.
音声認識への応用では,まず音声波形信号から音声特徴量ベクトルを10ミリ秒程度の固定された周期で抽出します.
そしてWFSTの入力シンボルに対応した各HMM状態における,各音声特徴量ベクトルのスコアを計算します.
ここまではWFSTの枠組の外です.
次に得られたスコアを各時刻ごとに対応するWFSTの枝重みに加えることで,WFSTを時間方向に展開します.
そして得られたネットワーク上で最小コストパス探索を行い,最小コストパスにそって出力シンボルを出力することで,入力音声に対応した単語出力を得ることが出来ます.